工業技術研究院資訊與通訊研究所 副所長/雲協技術專家委員會委員 黃維中
一一
一、前言
在過去的十年中,人工智慧已在生活和商業的各個領域的實際應用中證明了其價值。隨著運算速度顯著提升、運算成本顯著降低以及日趨成熟的演算法,深度學習技術在語音、文字內容、影片等資料類型的處理中被頻繁地導入到各個產業應用與日常生活中,從而創造出龐大的價值。在產業方面,人工智慧透過供應鏈管理優化、任務自動化派遣、製程改善等應用達到生產力和效率的提升 ; 在生活應用方面,人工智慧可提供個人化的服務和推薦,幫助醫療疾病診斷和治療規劃,亦可透過交通流量改善等智慧城市管理應用提升民眾生活品質,顯見目前人工智慧於產業與生活應用面上皆可有顯著助益並已站在全球發展的趨勢浪潮上。
然而,人工智慧廣泛應用除了推動產業投入外也吸引到了惡意攻擊者的目光,現今人工智慧所面臨之安全威脅包含對抗攻擊 (Adversarial Attacks)、模型竊取 (Model Stealing)、模型竄改 (Model Tampering) 與數據污染 (Data Poisoning)等惡意攻擊行為,惡意攻擊者目的在於竊取企業機敏資訊、規避偵測、散佈偽造資訊、社交工程攻擊等。其中,對抗攻擊乃指透過對於受測資料進行使用者無法察覺之改變,然而該改變足以讓人工智慧所使用之學習模型產生錯誤之判讀或預測結果,進而達到混淆人工智慧應用的目的。由於諸多智慧應用皆須仰賴精確之學習模型判讀結果,該攻擊將嚴重影響自動駕駛、用戶臉部識別、語音識別等人工智慧應用效能。
人工智慧應用的市場與普及化勢必需要搭建於安全可控的系統與算法之上,過往我國已有諸多案例 [12][13] 顯示缺乏資訊安全強固之產品欲進入國外市場時將遭遇嚴峻阻礙。因此,智慧應用開發者於導入算法時需要驗證模型與算法之安全性,安全涵蓋範圍包含演算法、模型、訓練資料集、測試資料集、應用程式介面與系統環境等,以避免貿然推動產品/服務上線後所造成之隱私、信譽與知識產權的損失。
一一
二、對抗樣本攻擊
目前全球主流算法之一為深度神經網路 (Deep Neural Networks,DNN),而深度神經網路相當遭受對抗攻擊,對抗攻擊所使用之對抗樣本是攻擊者為特定模型/算法所設計的帶有小幅擾動之惡意樣本,進而誤導深度神經網路做出錯誤的決策 (如圖1所示)。例如,攻擊者可以對自駕車需要識別和分類的交通標誌進行對抗攻擊,讓自駕車系統將停車標誌判讀為"繼續行駛"或其他標誌,進而導致人車意外的產生。此外,研究人員亦發現對抗樣本具有可遷移性 (transferability) [1],一種針對特定學習模型生成的對抗樣本也可以成功誤導其他模型的判斷結果,這意味著攻擊者可以在不了解底層模型的情況下欺騙人工智慧系統,因此將可大幅提高惡意樣本的實驗速度並增加可影響之應用領域範圍。
過往生成對抗雜訊的方法多利用深度學習模型和樣本的梯度生成,而非隨機產生,透過梯度在模型訓練中指引參數更新方向進而提高準確度。然而,在對抗攻擊所使用之對抗樣本中,透過微調輸入樣本的梯度方向,即使微小變化所造成的擾動也能顯著改變模型預測。因此,這種擾動能誘使深度學習模型產生錯誤預測,因此對抗雜訊成為有效的攻擊手段。 數位化對抗攻擊 (digital attacks) 是針對影像、語音、影片、文字等數位化資料製作對抗樣本,直接修改樣本數值以誤導人工智慧的判別預測。
數位化攻擊在正常影像中隱藏攻擊性擾動,難以被人察覺。相較於數位化攻擊,實體化對抗攻擊 (physical attacks) 對攻擊者來說更具挑戰性。在現實生活中,攻擊的對象經過相機或感測器的數位化轉換,破壞了精細的對抗擾動細節,而複雜的現實環境中存在亮度、遮擋等因素,降低了攻擊的有效性。然而,近期研究顯示[3][4][5],實體化對抗攻擊進一步損害了深度學習技術在現實生活中的實用性和可靠性。例如,製作對抗擾動影像並在列印前優化,或將對抗性干擾置入現實物體以欺騙檢測系統 (如圖2所示)。
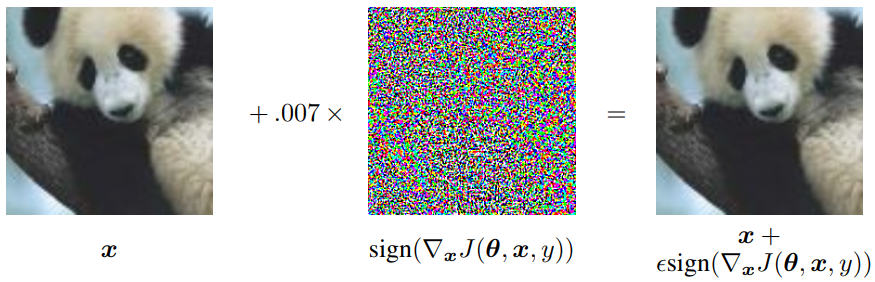 圖1 數位化對抗攻擊展示。"熊貓"影像經微調每個數值的梯度方向後,致AI模型將該樣本誤分類為"長臂猿"[2]
圖1 數位化對抗攻擊展示。"熊貓"影像經微調每個數值的梯度方向後,致AI模型將該樣本誤分類為"長臂猿"[2]
 圖2 實體化對抗攻擊展示。即使在多個角度下,YOLO目標檢測器也無法偵測穿著具有對抗擾動衣服的人[3][4]
圖2 實體化對抗攻擊展示。即使在多個角度下,YOLO目標檢測器也無法偵測穿著具有對抗擾動衣服的人[3][4]
一一
三、對抗樣本訓練
隨著攻擊研究的發展,防禦方法也在不斷演進。目前常見的防禦方式包括:
(1) 對抗訓練(adversarial training)[6][7],透過在訓練集中引入多樣的對抗樣本,強化模型對抗擾動輸入的能力;
(2) 利用輸入預處理和轉換等方法[8][9],限制輸入以過濾擾動;
(3) 建立基於對抗樣本和正常樣本的差異特徵偵測模組來過濾異常輸入[10]。
目前的主動式強化AI模型核心引入對抗訓練概念,將攻擊內容或現實中可能因AI訓練資料不足或缺漏造成AI誤判的資料,可使用多種對抗樣本生成方法,生成對抗樣本後代入AI訓練中進行優化改善,透過對抗訓練不斷地產生對抗樣本並重複代入AI訓練中進行優化改善,目前有大量的對抗樣本生成方法,其中迭代方法已被證明具有發現較強攻擊的對抗樣本能力,通常需要用更多的迭代來創建資料樣本,計算新資料樣本的對抗性擾動需要從頭開始,是相當耗時的問題,因此整體AI模型強韌性提升上效率很差。
工研院團隊與陽明交大游家牧教授的實驗室合作開發Meta Adversarial Perturbation (MAP)演算法[11],利用元學習 (Meta learning) 的概念來生成對抗樣本且MAP 之生成僅需 one-step update,使用元學習提高通用擾動的遷移性,在通用擾動的基礎上,再做一步的梯度更新,可以快速地針對不同模型快速產生對抗樣本且對抗樣本有很高的機率令AI模型誤判,加快強化AI模型的重訓練效率,改善AI模型核心穩健性 (Robustness) 和縮短訓練時長的效果。
一一
四、人工智慧安全法規
人工智慧的興起也推動了政府對於法規面的定立,歐盟 (European Union) 於2019年提出了「可信人工智慧倫理準則」 (Ethic Guidelines for Trustworthy AI),其中要項包含技術健全性與可靠性; 美國行政管理預算局 (United States Office of Management and Budget) 於2020年發布「人工智慧應用監管指南」(Guidance for Regulation of Artificial Intelligence Application),其中主要管理原則包含人工智慧風險評估管理、系統防護、措施安全性; 美國國家標準技術研究院 (National Institute of Standards and Technology,NIST) 於2023年發布「人工智慧風險管理框架」(AI Risk Management Framework,AI RMF),其中需求項目包含安全性、當責性 (Accountable)、可靠性、隱私安全、資訊安全,顯示政府法規推動的過程當中除了要求算法安全以及模型可靠,已漸漸重視應用面的安全風險。
而因應政府法規面的需求,非營利機構MITRE於2023年發布了「人工智慧系統對抗威脅框架」(Adversarial Threat Landscape for Artificial-Intelligence Systems,ATLAS)[14],MITRE為由美國聯邦政府資金挹注的研發機構,專注於美國國防部、聯邦航空總署與資安前瞻計畫,2013年所發布之「網路攻擊框架 ATT&CK」已是近十年資安研究人員主要參照指南,而MITRE所發布之人工智慧系統對抗威脅框架列出人工智慧攻擊流程各階段之策略與施行技術,包含偵查、資源開發、初期刺探、模型存取、攻擊執行、偵測規避、資料挖掘/蒐集、模型攻擊與滲透攻擊等。其中針對本文前述之對抗攻擊於框架中亦涵蓋於多個施行技術之中,包含搜尋公開可用的對抗性漏洞、搜尋公開可用之對抗生成ML模型/套件、對抗樣本繞過學習模型以及對抗樣本製作等,亦為主要示範案例攻擊手法之一,顯示對抗攻擊已是人工智慧攻擊主要攻擊應用手法之一。再者,該框架亦訂立系統安全層面之施行技術,強調人工智慧應用不能僅關注於算法與模型安全,包含系統環境、存取權限、應用服務介面以至於服務持續皆為營運方需要進行管理及安全測試之處。
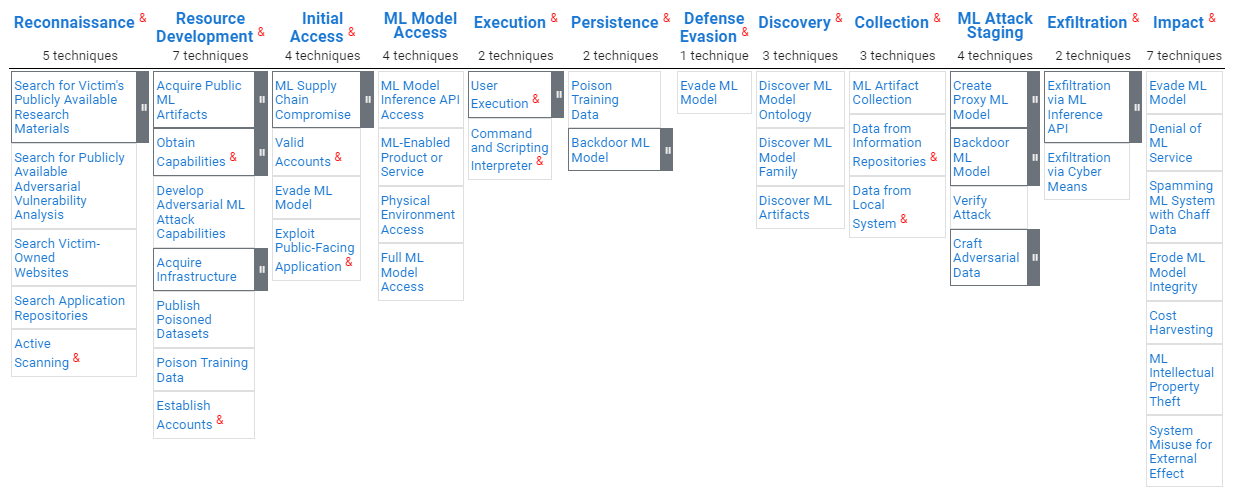 圖2 MITRE人工智慧系統對抗威脅框架 ATLAS [14]
圖2 MITRE人工智慧系統對抗威脅框架 ATLAS [14]
而人工智慧系統對抗威脅框架的發布亦讓產業有可依循方向,全球最大商業資安展會RSA近年皆會舉辦新創沙盒競賽 (Innovation Sandbox),公開評選出該年度最具前瞻性之新創企業,歷年近170家入圍者共計最後被收購超過75家,募資超過125億美元,其中每年冠軍更是當年度最受矚目的投資標的。本年度 (2023) 的新創沙盒冠軍為HiddenLayer,該司創立於2022年,產品為一人工智慧安全平台,該司聲稱其安全能力可以覆蓋 MITRE 人工智慧系統對抗威脅框架九成以上之威脅攻擊手法,並提供人工智慧應用相關資產之異常檢測和回應功能,並可以快速檢測出惡意對抗樣本。顯見,人工智慧安全已是產業重點關注標的,並且扣合政府法規與安全框架更是未來應用賦能廠商須依循的開發方向。
一一
五、結論
人工智慧為產業和民眾日常皆帶來了效益,包括產線效能提升、創新解決方案、個人化智慧服務等,然而接踵而來的資訊安全議題卻是相關應用更須正視的議題,相關惡意攻擊行為對於企業而言,可能因模型識別機制遭繞過或是信用評比機制失準而造成經濟損失,或是模型遭竊或遭濫用而導致企業信譽受損,以及相關知識產權的損失。因此,對於政府、企業、消費應用在積極導入人工智慧應用的同時,正視可能風險並對於威脅設計相關防範作為已是各式應用必須面對的重要課題。
對抗樣本攻擊對人工智慧的安全性提出了嚴峻挑戰,因為它們可能被利用來誤導模型,引發意外的判斷/預測結果,想像在未來自駕車應用場景中,若是一個貼著實體化對抗樣本之大型物件突然被推入車陣中,將會是對用路人一場嚴重的災難。研究人員正在努力開發對抗樣本防禦機制,包括設計穩定模型、對對抗樣本進行預處理、使用對抗訓練方法,配合國際政策法規與框架指引將可在人工智慧應用正式普及化前,確保其算法、模型與應用是安全、可靠且可信任的。
