中央研究院資訊科技創新研究中心 陳駿丞 副研究員
緣起
你聽過最近女星泰勒絲(Taylor Swift)的深偽色情圖片在社群平台X被瘋傳或是2021年我國的網紅深偽換臉事件的新聞嗎?這些偽造內容都是基於視覺生成式AI技術所產生,如早期知名的生成對抗網路(Generative Adversarial Network)技術可被用來生成許多逼真的人臉影像[Karras et al. 2019] [Karras et al. 2021],而生成對抗網路主要由一組生成器(Generator)與鑑別器(Discriminator)組成,生成器負責生成影像,而鑑別器則負責分辨影像是否是真實影像或電腦生成,兩者透過彼此互相競爭進行訓練,直到生成器可生成逼真的影像,由於生成對抗網路優異的性能,尤其是人臉生成(如圖一所示),該技術也催生出深偽軟體 (Deepfake) (專門用來生成換臉影片,後來“深偽”一詞更成為所有電腦偽造內容的代名詞),與一系列基於生成對抗網路的人臉影像和影片編輯軟體與線上服務,如 FaceApp [FaceApp 2021]、DeepFaceLab [DeepFaceLab 2021]、到最近的HeyGen [HeyGen 2023]、D-ID [D-ID 2023] 和FaceFusion [FaceFusion 2023],這些軟體不僅能生成極高品質的人臉合成影像或影片同時亦方便使用者能容易使用與存取,如HeyGen允許使用者上傳個人照片與聲音素材到其線上服務網站,透過幾個簡單操作即可快速生成深偽影片,品質之高一般普羅大眾很難辨別真偽。
此外,近期隨著深度生成模型的蓬勃發展與不斷推陳出新,擴散模型(Diffusion Model)已經成為新一代最受歡迎的生成模型[Ho et al. 2020][Rombach et al. 2022],擴散模型在訓練階段,透過對目標影像不斷進行加噪與去噪的過程進行學習,隨後的生成階段,即可透過對隨機取樣的噪聲影像進行不斷去噪即可產生高品質的影像(如圖二所示),與生成對抗網路不同,擴散模型的訓練更穩定,也比較不容易發生模式崩壞(Mode Collapse)的問題,因此可以使用更大規模的資料集進行訓練(如LAION-5B資料集),並用來產生除了人臉影像外更多元內容的高品質影像,比較知名的軟體與線上服務,如Midjourney [Midjourney 2023]、Stable Diffusion [Stable Diffusion 2023]與OpenAI的DALL·E-3 [DALL·E-3 2023]。除了影像生成,隨著OpenAI最近公開基於影片擴散模型的Sora模型,允許使用者透過輸入簡單的文字描述,生成約1分鐘的高品質短片,同時生成的影片的內容保持高度時間空間一致性,Sora這項技術的突破也造成各界對文字生成影片的生成式AI技術廣泛與高度關注,除了OpenAI、Google、NVidia、Microsoft、Meta等科技巨擘還有新創Runway和Pika Lab等公司都對相關視覺生成式AI技術有大量的投入。
 圖一、透過基於生成模型之深偽技術來修改人臉:換臉、人臉微調,影像來源:[Rössler et al. 2019]。一一
圖一、透過基於生成模型之深偽技術來修改人臉:換臉、人臉微調,影像來源:[Rössler et al. 2019]。一一 圖二、擴散模型前向加噪與反向去噪示意圖,影像來源:[Ho et al. 2020]。一一
圖二、擴散模型前向加噪與反向去噪示意圖,影像來源:[Ho et al. 2020]。一一
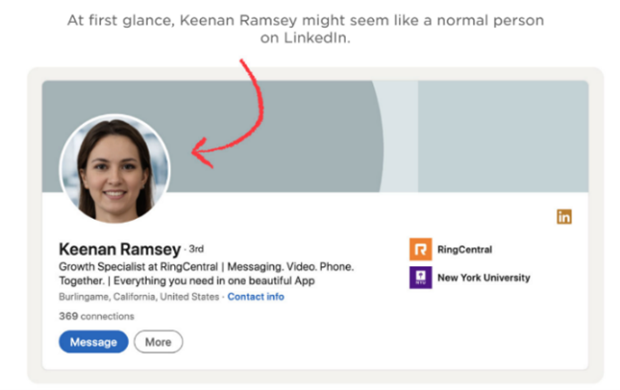
綜上所述,這些生成式AI模型的出現無疑為技術創新帶來了顯著進步,極大地簡化了內容創作流程,使人們能夠迅速且大量製作高質量的作品。然而,同時也激發了一系列關於隱私和抄襲的爭議。例如,一位叫做Sincarnate的用戶憑藉Midjourney服務創造的「太空歌劇院」在一場藝術競賽中贏得了首獎。此外,也有網友收集多張著名畫師Hollie Mengert的作品,通過微調Stable Diffusion生成類似風格的AI繪圖,引起了眾多藝術家的不滿和反對,他們抗議未經允許使用原創作品進行AI繪圖模型訓練與生成。同時,這些深度生成模型也可能被不擇手段的人用來大規模製作偽造內容和假新聞,如LinkedIn等知名社交網站上充斥大量的假帳號(如圖三所示),Facebook等其他平台也是如此。生成式AI技術的發展使得所見不再一定為真,有鑑於此,迫切需要投入深偽偵測技術和保護措施的相關研究,以確保公眾的照片和個人資料不被不法分子濫用,用於詐騙,從而維護人際間的信任。
 一一
一一 圖三、知名職業社交平台LinkedIn上發現大量利用深度生成模型產生的假用戶,從其頭像模糊的背景、消失的耳環等不自然的瑕疵,證明其電腦生成的圖片。
圖三、知名職業社交平台LinkedIn上發現大量利用深度生成模型產生的假用戶,從其頭像模糊的背景、消失的耳環等不自然的瑕疵,證明其電腦生成的圖片。
影像來源(https://www.npr.org/2022/03/27/1088140809/fake-linkedin-profiles?fbclid=IwAR3_ubq-9niHCYj10LeqlBogoMG9ExSMjz7azLhMlteu2D6-C-shsJhAKUE)。一一
 圖四、一些常見的生成瑕疵。影像來源: [Karras et al. 2019]、[Hui et al. 2022]、[Gandikota et al. 2023]。一一
圖四、一些常見的生成瑕疵。影像來源: [Karras et al. 2019]、[Hui et al. 2022]、[Gandikota et al. 2023]。一一
視覺深偽偵測技術簡介
隨著深偽技術的不斷發展,偽造內容的泛濫已經演變為一個重要的資訊安全問題,美國DARPA早在2016年就啟動了Media Forensics計畫,旨在開發關鍵技術來防止多媒體偽造內容的擴散。此外,DARPA更於2020年中啟動Semantic Forensics研究計畫,該計畫目標是讓機器能夠理解影像和影片中蘊含的語義信息,以進行更精確的偽造內容辨識和事件監測。科技公司,如Meta於2020年曾舉辦的深偽偵測挑戰賽,總獎金高達100萬美元,吸引了全球超過300個團隊參加,也凸顯深偽偵測的重要性及其日益增加的關注度。而在防禦方法中,深偽偵測是其中一種最受歡迎的策略,例如,通過收集包含真實和偽造影像的資料進行監督學習,利用深度學習或其他機器學習模型構建二元分類器來辨識數位內容的真偽,如初期的MesoNet [Afchar et al. 2018]和XceptionNet [Rössler et al. 2019]就是這類型方法的代表。但由於深偽技術的進步迅速,對於新技術生成的深偽內容,因為模型過擬合訓練資料導致其偵測性能會大打折扣,雖然可以透過持續收集大量的偽造資料並重新訓練來緩解這個問題,但這種作法不僅耗時且在實際操作中存在挑戰,如冷啟動問題(Cold Start),新的深偽內容剛出現的時候,可供收集與訓練用的資料數量有限。因此,有些研究工作將目標鎖定在探究生成模型的限制,利用已知深偽技術在生成影像時,可能造成的視覺瑕疵或不合理之處當作偵測依據,或透過監督式或自監督式預訓練等方式,以設計泛化能力強的偵測模型。常見瑕疵包括背景模糊、人臉閃爍、臉部輪廓與背景接合處是否不自然、影片跨幀或有遮擋等大幅度動作時臉部是否有閃爍、語音和嘴型是否同步、手指生成是否有瑕疵或個數不對等問題(如圖四所示),另外,就算完美如Sora的模型,目前在手的生成與保持物體在時間上的一致性上仍可能出錯 [Sora Flaws 2024],這類泛化深偽偵測研究的代表有Face X-Ray [Li et al. 2020] 檢測臉部邊界瑕疵、EyesTellAll [Hui et al. 2022] 檢測瞳孔是否是不規則的形狀、LipsForensics [Haliassos et al. 2021] 檢測唇部動作是否自然、RealForensics [Haliassos et al. 2022] 檢測臉部動作是否自然、FTCN [Zheng et al. 2021] 偵測影片的時間一致性、AltFreezing [Wang et al. 2023] 和TALL-Swin則檢測影片的空間與時間一致性、SBI [Shiohara et al. 2022] 基於自監督學習,透過融合真實與經過資料擴增的影像模擬深偽影像,提高模型訓練效率和深偽偵測的泛化性能。但如何用少量的資料有效讓深偽偵測器適應新的深偽內容或用既有資料訓練泛化能力更強的模型,仍然是非常挑戰的研究問題,為了加強偵測的有效性與泛化性,最新的研究,如[Ojha et al. 2023] [Sha et al. 2023],利用OpenAI公布的CLIP模型[Radford et al. 2021]當作特徵抽取器配合簡單的分類器,在生成對抗網路和擴散模型生成的影像資料上達到不錯的偵測效果,因為CLIP模型預訓練在4億對影像文字配對的資料集上,其特徵擁有非常好的泛化性,這也證明利用如CLIP這樣的基石模型(Foundation Model)配合適當的適應器(如LoRA[Hu et al. 2021]),是一個研究泛化性佳之深偽偵測器可行的方向。
除了深偽偵測的手段外,有研究透過對抗樣本攻擊來防禦,將難以察覺的干擾添加到輸入影像中,讓深偽模型的輸出無法產生預期的效果(如圖五(a)所示),從而保護內容免於被不當使用,如美國芝加哥大學 Ben Zhao 教授領導的團隊,開發名為 GLAZE 的 AI 繪圖防禦工具 [Shan et al. 2023],其想法即是基於對抗樣本的概念,因此,透過 GLAZE 保護的圖片,當惡意使用者要使用它們微調AI繪圖的模型,進行類似風格的創作,將無法產生他們想要的結果。此外,將隱形數位浮水印嵌入影片內容中,使內容擁有者或公眾能夠通過內嵌的浮水印訊息更有效地辨識內容真偽,也是一種有效的防禦手段,如有研究在訓練資料中添加隱形數位浮水印 [Yu et al. 2021],以這些資料訓練出的深偽模型生成的內容也會包含這些浮水印,透過提取浮水印便能辨別內容的真偽,如圖五(b)所示。
總而言之,隨著深偽技術的持續進步,防禦方法也在不斷創新和發展,從基於瑕疵識別的偵測技術到利用對抗樣本的攻擊策略,再到利用數位浮水印進行內容保護,雖然這些方法各有優缺點,但結合使用能夠提供更全面的防禦機制,以對抗日益精進的深偽造假技術。
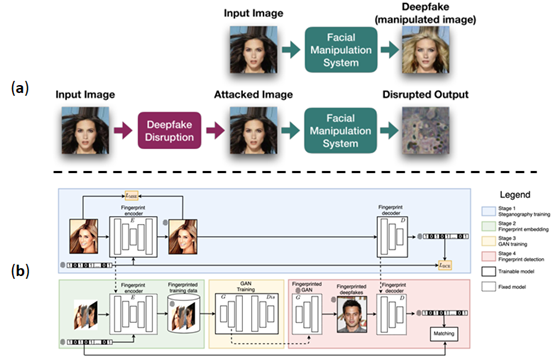 圖五、(a) 產生對抗樣本讓影像遷移模型生成影像壞掉,影像來源: [Ruiz et al. 2020],(b)基於隱形數位浮水印之深偽內容追蹤與驗證系統架構圖,在訓練資料每張圖像添加二元字串浮水印,
圖五、(a) 產生對抗樣本讓影像遷移模型生成影像壞掉,影像來源: [Ruiz et al. 2020],(b)基於隱形數位浮水印之深偽內容追蹤與驗證系統架構圖,在訓練資料每張圖像添加二元字串浮水印,
影像來源: [Yu et al. 2021]。一一
結語
隨著生成式 AI 技術的快速進步,上述的保護方法,也許很快就會被有心人士破解,因此,當人們沉浸於生成式 AI 帶來的便利,也應該考慮它可能帶來的威脅,並對於相關的保護與防衛技術同樣投入大量的研究,包括:生成內容依據的來源追蹤、AI生成內容偵測、更穩健的數位浮水印或攻擊力更強對抗樣本等研究,提供線上偵測服務方便民眾使用,如[Deepware 2021] [AI-or-Not 2023],AI讓大眾都能放心地使用生成式AI的服務。而且現在不只影像與影片、文字、聲音等數位內容都有相對應的深偽模型,除了技術的開發,更要普及民眾對相關技術的認識,小心保護自己的資料,與提高自身的警覺,以避免各種新型態的詐騙,如用深偽換臉技術進行視訊詐騙。
參考資料
- [Sora Flaws 2024] Flaws in OpenAI’s Sora Make It Possible to Detect Fake Videos, WSJ Videos. (https://www.wsj.com/video/series/wsj-explains/flaws-in-openais-sora-make-it-possible-to-detect-fake-videos/BFD0F451-5C7C-4585-B6C9-B6D6FEA26469)
- [Midjourney 2023] https://www.midjourney.com/home
- [Stable Diffusion 2023] https://stability.ai/
- [DALL·E-3 2023] https://openai.com/dall-e-3 [Ho et al. 2020] Ho, Jonathan, Ajay Jain, and Pieter Abbeel. "Denoising diffusion probabilistic models." Advances in Neural Information Processing Systems 33 (2020): 6840-6851.
- [Rombach 2022] Rombach, Robin, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. "High-resolution image synthesis with latent diffusion models." In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10684-10695. 2022.
- [Afchar et al. 2018] Afchar, Darius, Vincent Nozick, Junichi Yamagishi, and Isao Echizen. "Mesonet: a compact facial video forgery detection network." In 2018 IEEE international workshop on information forensics and security (WIFS), pp. 1-7., 2018.
- [Yu et al. 2021] Yu, Ning, Vladislav Skripniuk, Sahar Abdelnabi, and Mario Fritz. “Artificial fingerprinting for generative models: Rooting deepfake attribution in training data.” In IEEE/CVF International Conference on Computer Vision (CVPR), pp. 14448-14457. 2021.
- [Ruiz et al. 2020] Ruiz, Nataniel, Sarah Adel Bargal, and Stan Sclaroff. “Disrupting deepfakes: Adversarial attacks against conditional image translation networks and facial manipulation systems.” In European Conference on Computer Vision (ECCV), pp. 236-251. Springer, Cham, 2020. [Karras et al. 2019] Karras, Tero, Samuli Laine, and Timo Aila. “A style-based generator architecture for generative adversarial networks.” In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4401-4410. 2019.
- [Karras et al. 2021] Karras, Tero, Miika Aittala, Samuli Laine, Erik Härkönen, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. “Alias-free generative adversarial networks.” In Neural Information Processing Systems (NeurIPS). 2021.
- [Rössler et al. 2019] Rossler, Andreas, Davide Cozzolino, Luisa Verdoliva, Christian Riess, Justus Thies, and Matthias Nießner. “Faceforensics++: Learning to detect manipulated facial images.” In IEEE/CVF International Conference on Computer Vision (ICCV), pp. 1-11. 2019.
- [FaceApp 2021] https://www.faceapp.com/
- [DeepFaceLab, 2021] https://github.com/iperov/DeepFaceLab
- [FaceFusion, 2023] https://github.com/facefusion/facefusion
- {HeyGen, 2023} https://app.heygen.com/
- [D-ID, 2023] https://www.d-id.com/
- [AI-or-Not, 2023] https://www.aiornot.com/
- [Deepware, 2021] https://scanner.deepware.ai/
- [Li et al. 2020] Li, Lingzhi, Jianmin Bao, Ting Zhang, Hao Yang, Dong Chen, Fang Wen, and Baining Guo. "Face x-ray for more general face forgery detection." In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5001-5010. 2020.
- [Hui et al. 2022] Guo, Hui, Shu Hu, Xin Wang, Ming-Ching Chang, and Siwei Lyu. "Eyes Tell All: Irregular Pupil Shapes Reveal GAN-generated Faces." In International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2022.
- [Zheng et al. 2021] Zheng, Yinglin, Jianmin Bao, Dong Chen, Ming Zeng, and Fang Wen. "Exploring temporal coherence for more general video face forgery detection." In IEEE/CVF International Conference on Computer Vision (ICCV), pp. 15044-15054. 2021.
- [Haliassos et al. 2022] Haliassos, Alexandros, Rodrigo Mira, Stavros Petridis, and Maja Pantic. "Leveraging real talking faces via self-supervision for robust forgery detection." In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 14950-14962. 2022.
- [Haliassos et al. 2021] Haliassos, Alexandros, Konstantinos Vougioukas, Stavros Petridis, and Maja Pantic. "Lips don't lie: A generalisable and robust approach to face forgery detection." In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5039-5049. 2021.
- [Xu et al. 2023] Xu, Yuting, Jian Liang, Gengyun Jia, Ziming Yang, Yanhao Zhang, and Ran He. "TALL: Thumbnail layout for deepfake video detection." In IEEE/CVF International Conference on Computer Vision (ICCV), pp. 22658-22668. 2023. [Wang et al. 2023] Wang, Zhendong, Jianmin Bao, Wengang Zhou, Weilun Wang, and Houqiang Li. "Altfreezing for more general video face forgery detection." In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4129-4138. 2023.
- [Shiohara et al. 2022] Shiohara, Kaede, and Toshihiko Yamasaki. "Detecting deepfakes with self-blended images." In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 18720-18729. 2022.
- [Shan et al. 2023] Shan, Shawn, Jenna Cryan, Emily Wenger, Haitao Zheng, Rana Hanocka, and Ben Y. Zhao. "Glaze: Protecting Artists from Style Mimicry by Text-to-Image Models." In 32nd USENIX Security Symposium (USENIX Security 23), pp. 2187-2204. 2023.
- [Hu et al. 2021] Hu, Edward J., Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. "Lora: Low-rank adaptation of large language models." arXiv preprint arXiv:2106.09685 (2021).
- [Ojha et al. 2023] Ojha, Utkarsh, Yuheng Li, and Yong Jae Lee. "Towards universal fake image detectors that generalize across generative models." In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 24480-24489. 2023.
- [Sha et al. 2023] Sha, Zeyang, Zheng Li, Ning Yu, and Yang Zhang. "De-fake: Detection and attribution of fake images generated by text-to-image generation models." In ACM SIGSAC Conference on Computer and Communications Security (CCS), pp. 3418-3432. 2023.
- [Radford et al. 2021] Radford, Alec, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry et al. "Learning transferable visual models from natural language supervision." In International Conference on Machine Learning (ICML), pp. 8748-8763. PMLR, 2021.
- [Gandikota et al. 2023] Gandikota, Rohit, Joanna Materzynska, Tingrui Zhou, Antonio Torralba, and David Bau. "Concept sliders: Lora adaptors for precise control in diffusion models." arXiv preprint arXiv:2311.12092 (2023).
