黃彥男 中央研究院資訊科技創新研究中心特聘研究員、雲協技術專家
李思壯 淡江大學資訊傳播學系助理教授
一、前言
自從網際網路開放商用以來,網路已經成為一般民眾取得訊息管道的主要來源,其重要性與日俱增。根據台灣網路中心「2020台灣網路報告」,目前台灣12歲以上民眾的上網率達83.0%,其中使用無線上網的比率為79.3%。民眾使用率最高的服務依序為即時通訊(95.6%)、網路新聞(80.3%)、社群論壇(80.1%)、影音/直播(77.0%)、電子郵件/搜尋(70.7%)。在上述功能中,除了即時通訊與電子郵件較屬於個人的點對點通訊之外,其他各式服務仍以內容的提供為主。廣告向來都是內容提供者的重要收益來源之一。由於網際網路上的內容提供者眾多,廣告網路(Advertising Network)扮演中間的橋樑,讓內容提供者與廣告主均能將自身的版面需求與供給資訊登錄到廣告網路上,再由廣告網路服務進行自動化的撮合刊登,Google提供的AdSense就是其中的代表。內容提供者將Google所提供的程式碼置放於網站內,Google就可根據網站的內容自動推送廣告。當網站訪客造訪網站,看到廣告出現甚或是進一步點擊廣告時,廣告主即須支付廣告費給予內容網站。透過此一機制,內容提供者可更專注於製作內容以及以行銷活動吸引網路使用者,而將透過網路廣告獲取收益的各個技術及業務開發環節,交給廣告網路來處理。
為了吸引更多網站造訪者以獲得廣告收益,利用社群媒體將引導流量為內容網站的主流策略之一。內容提供者競相使用社群媒體宣傳自身的內容,各社群平台也各有一套基準決定哪些貼文要推送給哪些使用者,一昧的大量張貼並不能確保內容的曝光,甚至可能因為張貼浮濫而造成反效果。以臉書為例,於2018年公開表示將改以「有意義的互動」做為內容排序的標準,而期間未公開的演算法調整也不知凡幾 。對內容提供者而言,在張貼前預知哪些內容可能獲得較佳互動十分困難。一旦在一定的期間內張貼過多互動不佳的內容,後續所張貼的內容就會因為排序過低而難以觸及使用者,形成惡性循環。在因應手段有限的情況下,社群小編往往只能依賴過去的經驗,將近期內容包裝成可能獲得較佳互動的形式投放。近期機器學習技術的進展則有可能協助內容提供者減緩此一問題。由於社群網站會提供應用程式介面(API, application programming interface)給予商用帳號擁有者,如果能取得過往投放內容與各項績效數據的對應,如使用者觸及數、反應數、甚至是導流到內容網站後之廣告收益,就可以嘗試建立預測模型,在內容於社群網站張貼前預判可能達成的效果,進而提升有效投放的比例,讓投放內容可以持續有效地接觸到受眾,也避免後續張貼內容時因先前內容互動不良,而影響到使用者觸及。
一一
二、建立貼文社群績效預測模型的準備工作
預測模型可以協助我們在社群媒體的貼文張貼前,預測其張貼後的成效。如果一則貼文的預期的張貼成效不佳,可能會影響到後續貼文的觸及使用者的機會,此時放棄張貼可能是較佳的選擇。建立預測模型必須透過監督式學習(supervised learning)進行。首先必須準備足夠數量的資料,資料中須納入貼文的各項特性,如張貼時間、張貼社群的訂閱人數、張貼內容、張貼時搭配的圖片特性等,再挑選張貼後的績效指標之一如觸及數、反應數、留言數、廣告收入等做為預測標的,再透過機器學習演算法建立預測模型,以張貼前可取得之各項潛在因素,預測實際張貼績效。在研究案例中,經營內容網站的廠商利用社群媒體創造網站流量,但面臨流量日益下降,增加貼文數量卻帶來反效果的困境,希望透過預測模型的建立緩解甚至改善此一問題。合作廠商提供Facebook以及Google Analytics的管理帳號以及所張貼文章的完整標題及內容資訊,研究團隊則透過平台的管理帳號串接API,取得各項細節資料。至此,進行監督式學習所需要的各項原始資料已經齊備,經過後續資料清理的程序,即可用於訓練預測模型。
在預測標的的選擇方面,當使用者能夠觀看並點擊廣告時,表示使用者已經點入貼文抵達內容網站,且廣告收益也是合作廠商經營網站最主要的目的,因此我們從各項社群貼文績效指標中,選擇廣告收入做為績效指標。在預測用特徵的處理方面,社群訂閱人數、張貼之時段等變數可直接使用,而文字、圖片中所透露的特徵則需要另行處理。貼文的文字特徵研究團隊利用Google自然語言API解析出其中的關鍵字及文章分類,貼文配圖的特徵則利用Google Vision API取得配圖的解析度高低做為預測變數。
一一
三、完成預測模型之訓練,並運用之提升張貼效率
監督式學習一般可分為分類(classification)方法以及迴歸(regression)方法,前者係指根據輸入資料輸出一個類別,例如貼文是否具有獲得高廣告收益的潛力,後者則是輸出數字,例如廣告收益的金額,兩者都可以供決策者輔助決策。經過初步測試,迴歸方法的成效不佳,研究團隊改採使用分類方法進行評估。由於各類網路內容之流量往往集中於少數內容,因此依據文章的廣告收益將前百分之十定義為高績效貼文,其他則為一般收益貼文,將資料標籤加入訓練資料集。研究團隊選定決策樹、XGBoost以及深度學習網絡等三項演算法進行模型訓練,以探討各個模型對提升張貼效率可能的貢獻。由於所使用的訓練資料屬於兩種標籤數量差異較大的資料集,因此在訓練過程中採取多種不同的再取樣方法,讓兩種標籤資料的數量較為接近,以取得較佳的訓練效果。
在評估預測模型時,正確率是最常被使用的評估指標,並可以直接以數量較大的標籤的比率為基準正確率(baseline),是故本案例之基準正確率即為百分之九十,如下表中的ZeroR分類方法。將三種演算法與多種資料再取樣方法搭配後,並未能獲得顯著超過百分之九十正確率的結果。由於研究團隊的關注焦點在於能透過預測模型協助提升社群媒體之投放效率,因此進一步觀察各個預測模型之混淆矩陣(confusion matrix)。混淆矩陣可以協助我們評估使用預測模型可以達到的效果,例如後表中的ZeroR分類方法為例,Y軸為文章依據客觀資料是屬於一般收益或高收益貼文,X軸則為貼文會被預測模型分類為一般收益或高收益,其中被預測為高收益的貼文會被發出。這些數據可以協助社群管理者可依其策略目標的不同選擇預測模型。社群管理者如果當時希望追求短期的廣告收益最大,則可以容忍較多將一般收益貼文誤判為高收益貼文而發出的情況,而選擇盡可能發出最多貼文。反之如果社群管理者發現貼文的觸及率日益降低,則可以選擇更謹慎地貼文,避免使用會將許多一般收益貼文誤判為高收益貼文的分類方法。
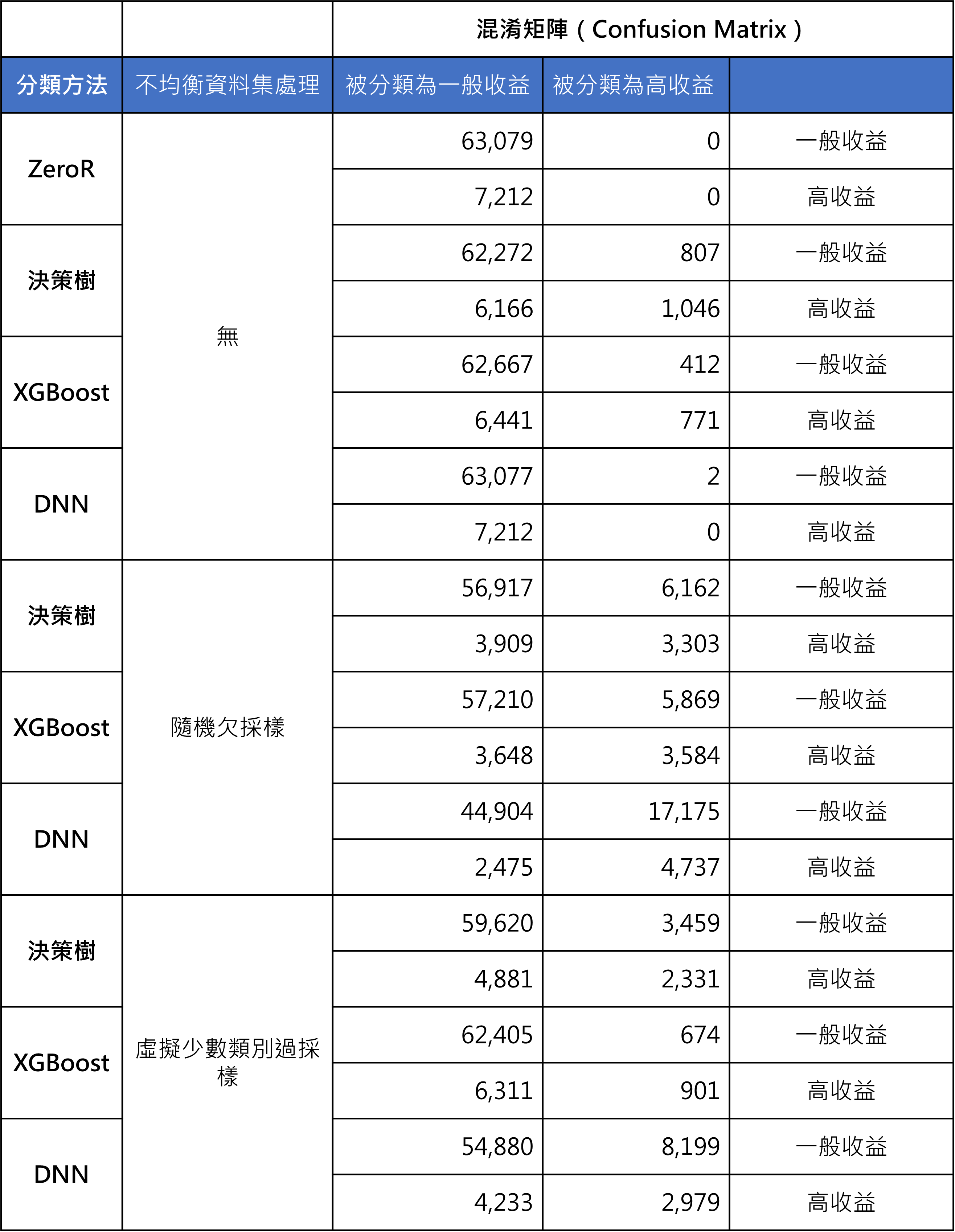
資料來源:本文整理
以前表為例,如果希望所張貼的貼文中高績效的貼文比例達到最高,可選擇XGBoost演算法搭配虛擬少數類別過採樣之資料。以此組合所訓練出的模型進行預測,並發出預測為高績效之貼文,則在70291則驗證資料中僅會選擇1575則貼文發出,其中有57%為真正的高收益貼文。此一預測模型的缺點是僅有低比例的貼文會被此預測模型判斷為應發出的貼文,且實際發出的高收益貼文數量更少。另一方面,如果以盡可能發出最多的高收益貼文為目標,則最佳的預測模型為經過資料欠採樣處理之DNN深度學習模型為最佳模式,此時在70291則驗證資料中有4737篇會被判斷為高績效貼文被發出,缺點為會連帶送出17175則一般收益之貼文。但總發出的貼文數21912比起完全不過濾的70291篇,仍可大幅降低69%,除此二種組合外,上表中尚有多種預測模型可供採用,內容網站之經營者可隨當時之需要不同,在短期收益以及長期永續經營之間做取捨,選擇適當之預測模型。
一一
四、結語
從以上的結果我們可以得知,預測模型的建立有助於社群媒體經營者根據當前社群平台的演算法情況調整自己的投放策略。誠然,社群平台之演算法也是處於動態調整的狀態,因此預測模型也需要每隔一段時間進行更新,方能反應平台的實況。至於在各個預測模型中應採取何者為佳,還須看內容網站經營者之經營需求為何。以本文的各項資料為例,如果已觀察到所經營的社群媒體帳號有觸及率逐漸降低的情形,則應減少貼文數。如果社群媒體帳號的觸及狀態尚稱穩定,則可選擇總收益較佳的預測模型。社群媒體已經從與朋友間的交流媒介,轉變成獲取多樣化內容的管道。對內容網站而言,妥善運用社群媒體不只是增加競爭力的途徑,更是永續經營的基本要素。善用機器學習則可以讓內容提供者在經營社群媒體時,除了依賴小編的經驗法則外,多一分決策的依據。
